在成功地测量了Spine-Triton中编写的融合算子的性能之后,下一步就是要找到性能不如PyTorch算子的原因。这时候,就需要查看自定义的算子对应的汇编代码。
先上结论:
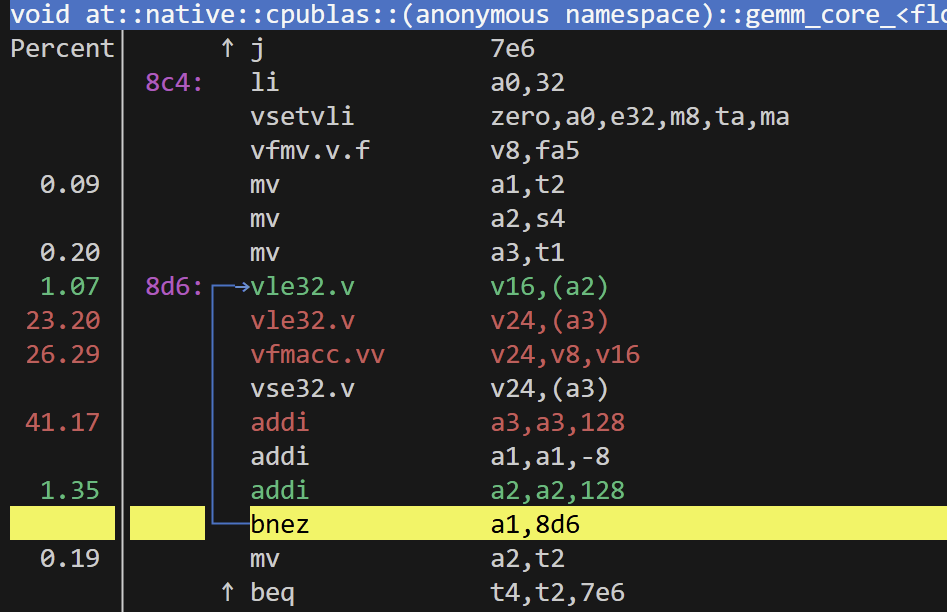
- PyTorch的算子torch.matmul()使用了矢量指令完成矩阵乘法
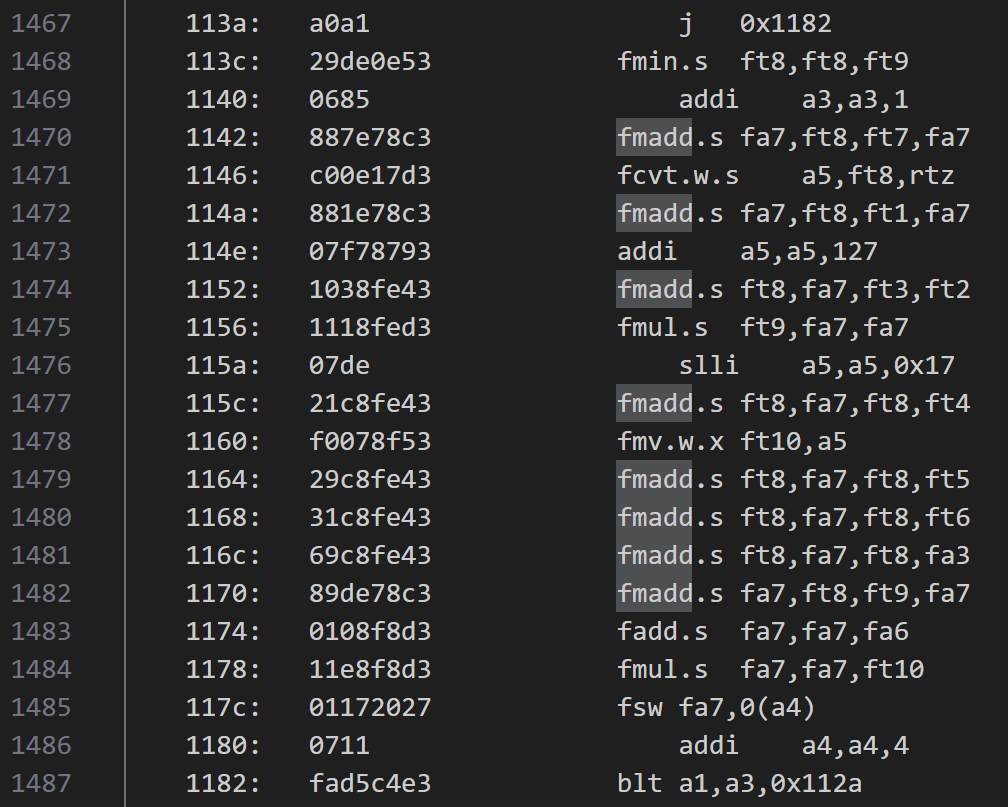
- Spine-Triton编写的融合算子中矩阵乘法部分是用标量指令实现的
再上图:
- PyTorch算子调用了void at::native::cpublas::(anonymous namespace)::gemm_core_<float, float, float>,汇编代码:
- Spine-Triton编写的融合算子汇编代码:
最后给出查看汇编指令的方法:
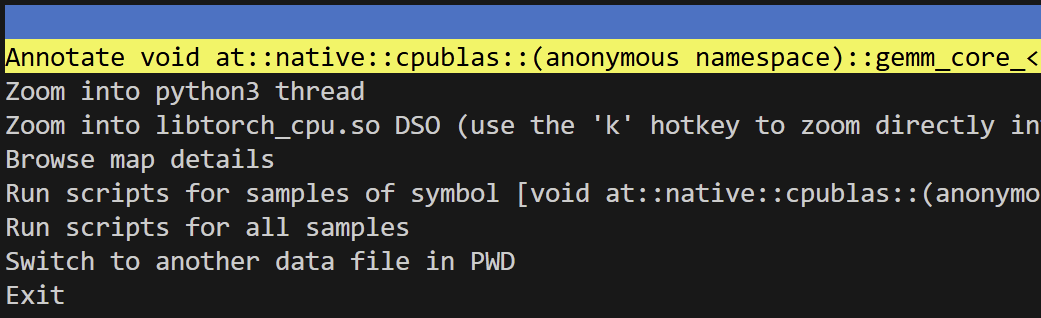
- 通过perf查看PyTorch算子对应的汇编语句
安装和使用perf的命令可以参考Bianbu RDK的文档perf + FlameGraph 使用教程和论坛的帖子Almost same execution time when enabling auto-vectorization or not。向大佬们致敬!
perf record -e u_mode_cycle python3 python/examples/test_fused_mm_softmax.single_run.py
perf report

- 通过ir_dumps获得编译后的二进制文件,反汇编查看指令
export SPINE_TRITON_DUMP_PATH=./ir_dumps
mkdir ir_dumps
python3 python/examples/test_fused_mm_softmax.single_run.py
objdump -D -b binary -m riscv:rv64 ir_dumps/bare_fused_mm_softmax_.o > ir_dumps/bare_fused_mm_softmax_.o.dmp
ir_dumps.zip (96.7 KB)
汇编指令说明
vfmacc :: Vector Floating-Point Instructions — RVV-web-page documentation
fmadd.d :: RISC-V Specification for example_rv64_with_overlay
题外话:perf生成的trace是可以导出为火焰图的。但是对于RISC-V架构中Python函数名解析的支持还未生效。
PYTHON_PERF_JIT_SUPPORT=1 perf record -F 99 -a -g -e cpu-clock python3 python/examples/test_fused_mm_softmax.single_run.py
perf script > out.perf
mv out.perf ../perf/.
cd ../perf/.
./git-FlameGraph/stackcollapse-perf.pl out.perf > out.folded
./git-FlameGraph/flamegraph.pl out.folded > out.svg
用浏览器打开out.svg,搜索gemm,就可以找到PyTorch算子对应的二进制程序,如下图中紫色部分所示:
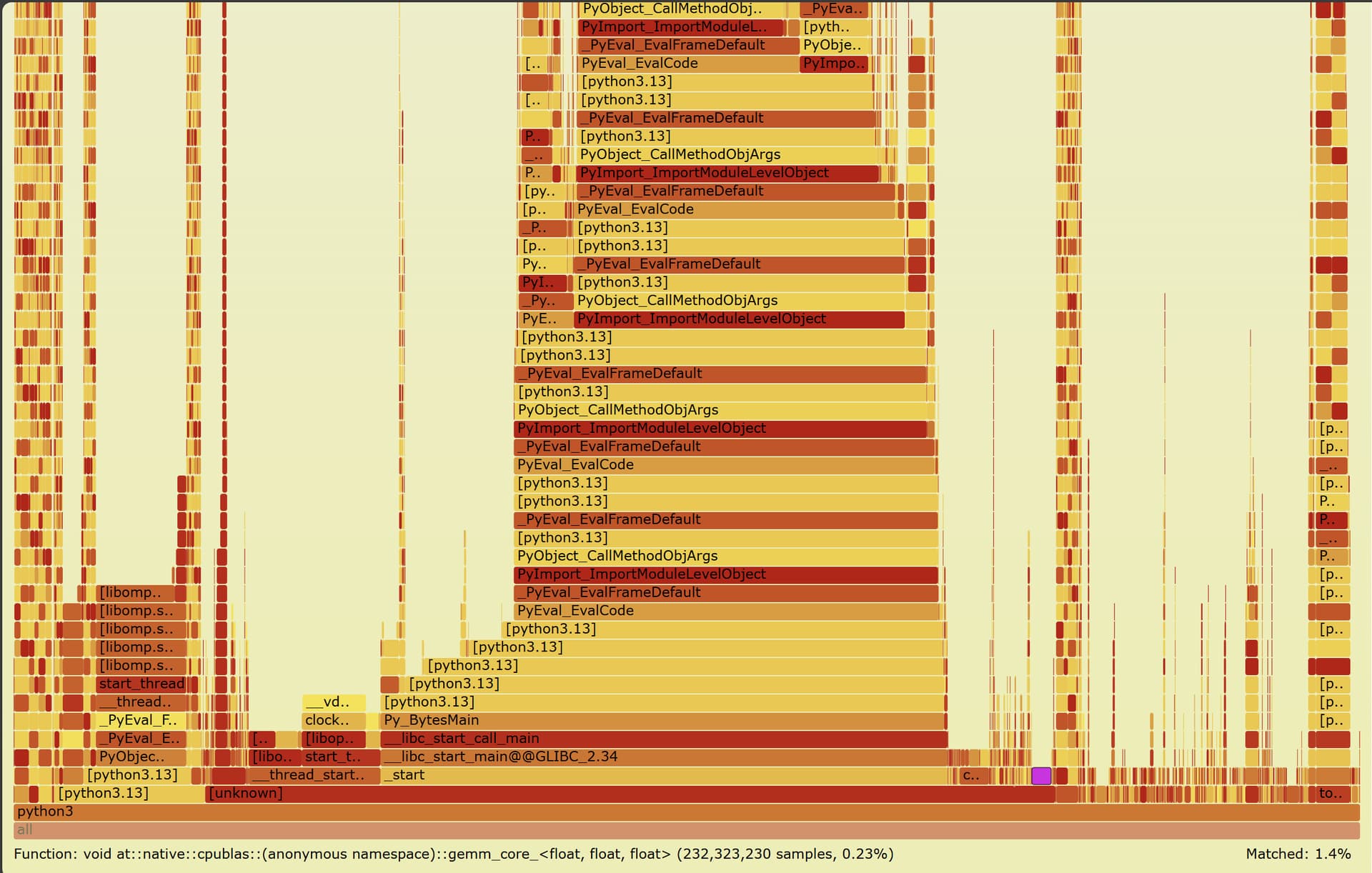
上面的命令中,虽然使用环境变量PYTHON_PERF_JIT_SUPPORT=1打开了对Python函数名解析的支持,但是上图中还是存在大量的[python3.13]这样的缺省命名。
尝试查看perf对Python函数名解析的支持,得到如下的结果:
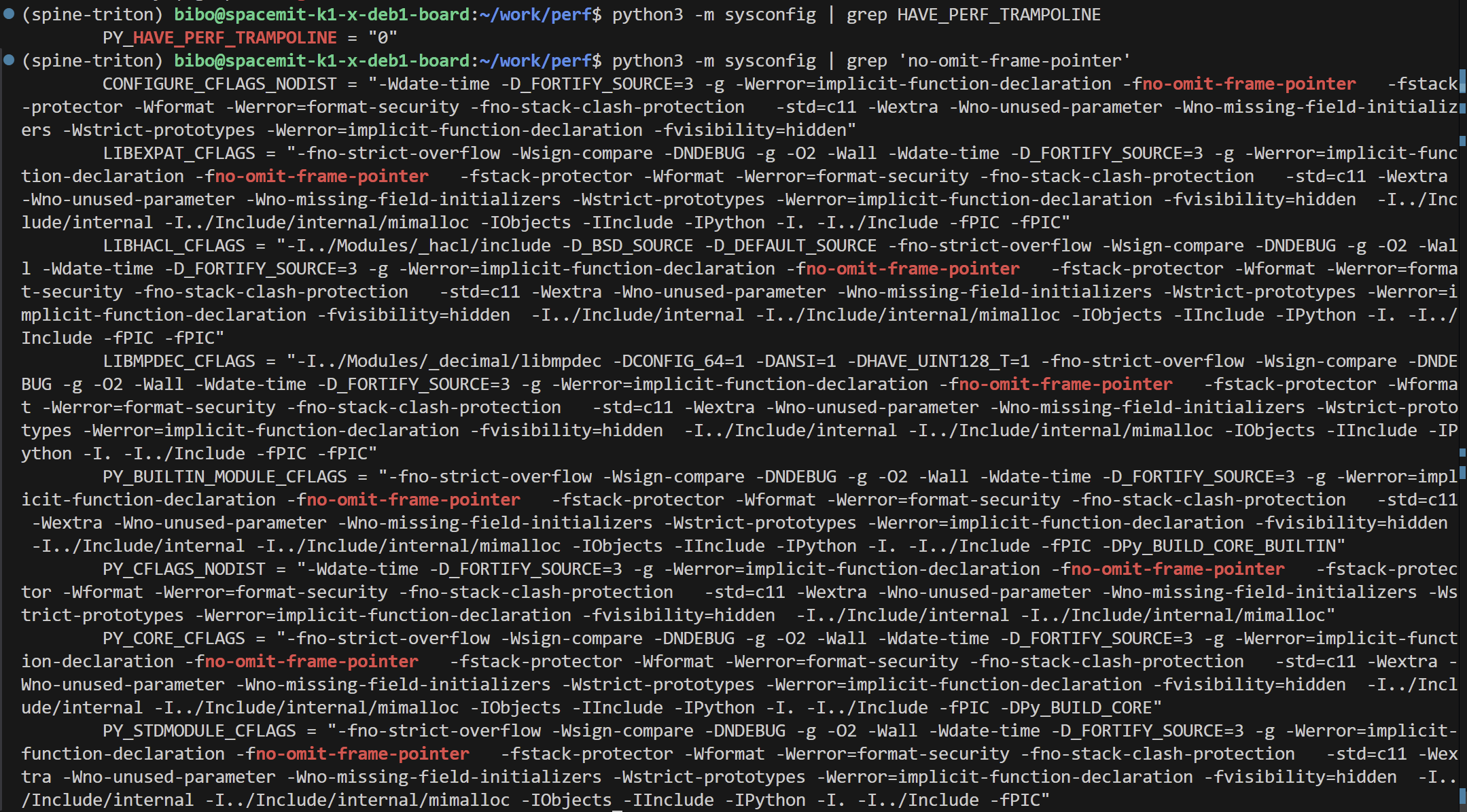
虽然Python已经支持perf了:Python 对 Linux perf 性能分析器的支持 — Python 3.12.12 文档
但是RISC-V架构上还是空白:聊聊 Python 3.12 中 perf 的原生支持 | Manjusaka