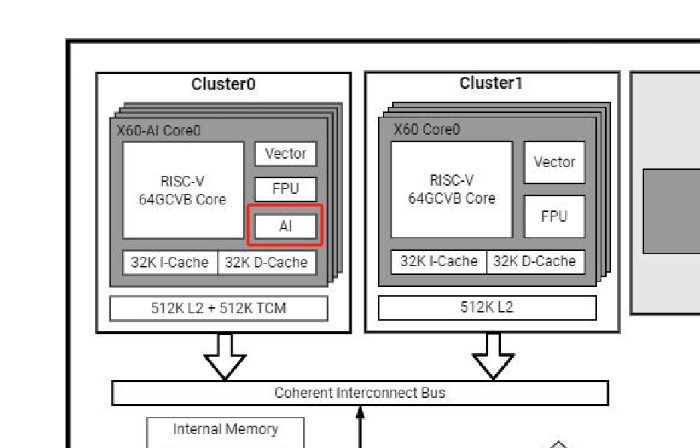
K1的CPU分为两个Cluster,Cluster0中实现了AI的相关指令(IME扩展,vmadot指令等)
https://developer.spacemit.com/documentation?token=AJXZwPidOiPqIjk17bgc2R1QnQh
使用这个文档中的cpufp项目测试K1上的IME扩展的性能
./cpufp --thread_pool=[0-7]这个命令使用K1的8个核心运行,但实际上由于程序中包含IME扩展指令,这部分指令必须由Cluster0的CPU运行,最终只有核心0~3在跑程序,无法利用到8核的性能