riple
1
我创建了一个项目,用来测量K1上使用IME加速GEMM能够得到的效率,并用Roofline Model来展示结果:RSPwFPGAs/roofline_model_spacemit_k1
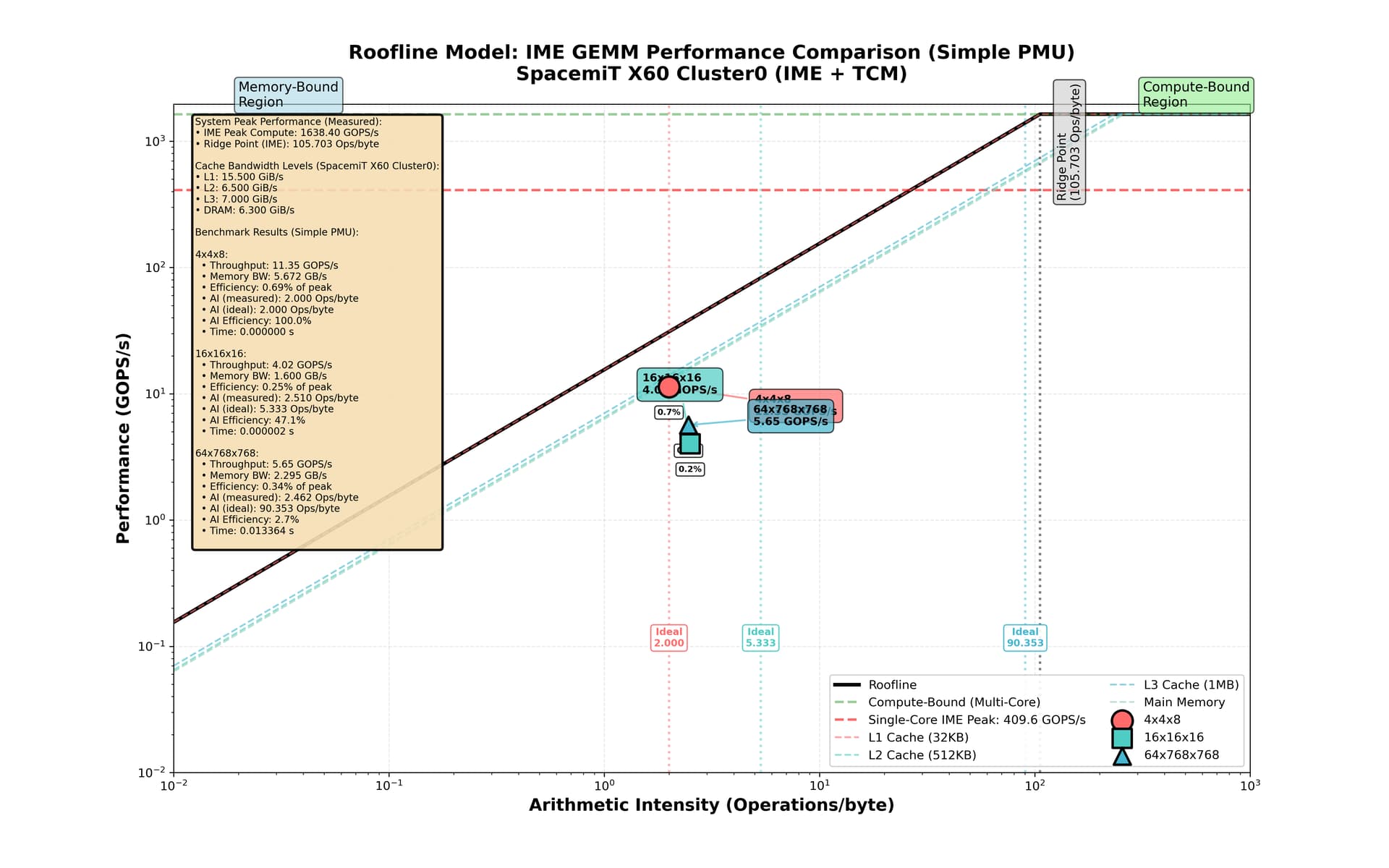
当前在MxNxK为4x4x8, 16x16x16, 64x768x768三种尺寸的矩阵乘法上测得的性能如下图所示。其中算数强度(AI)的理想值被标注出来,实测值作为性能测试结果的横坐标值。
从图中可以看到,16x16x16与64x768x768内核的性能远未达到性能峰值。其中一个重要原因是它们实现的内核算数强度(Arithmetic Intensity)偏离理想值很远。
恳请社区和进迭时空的专家们给与指导。
riple
2
riple
3
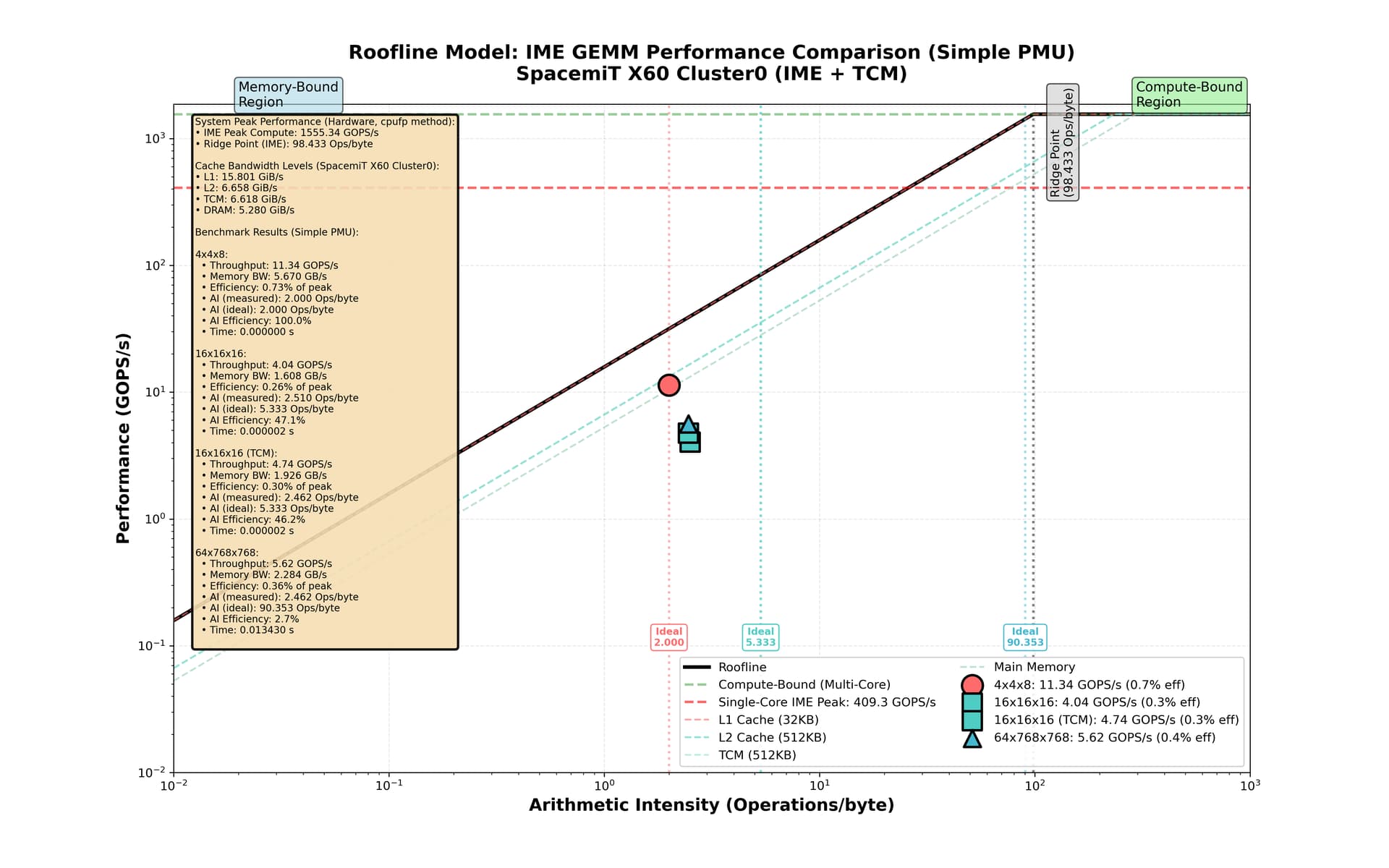
新增加了使用TCM的16x16x16的例子,性能有所提升。
图中性能百分比是基于4核性能计算的,由于例子中只使用了单核,百分比应该乘以4。
本方法采用实测算数强度(AI)值标示性能测量点的横坐标。采用实测而非理想算数强度值的好处是,揭示出:由于Vector寄存器数量与容量的限制,冗余的load/store操作是不可避免的,这就造成实际AI值比理想AI值小很多,限制了IME性能的发挥。
1 个赞
riple
4
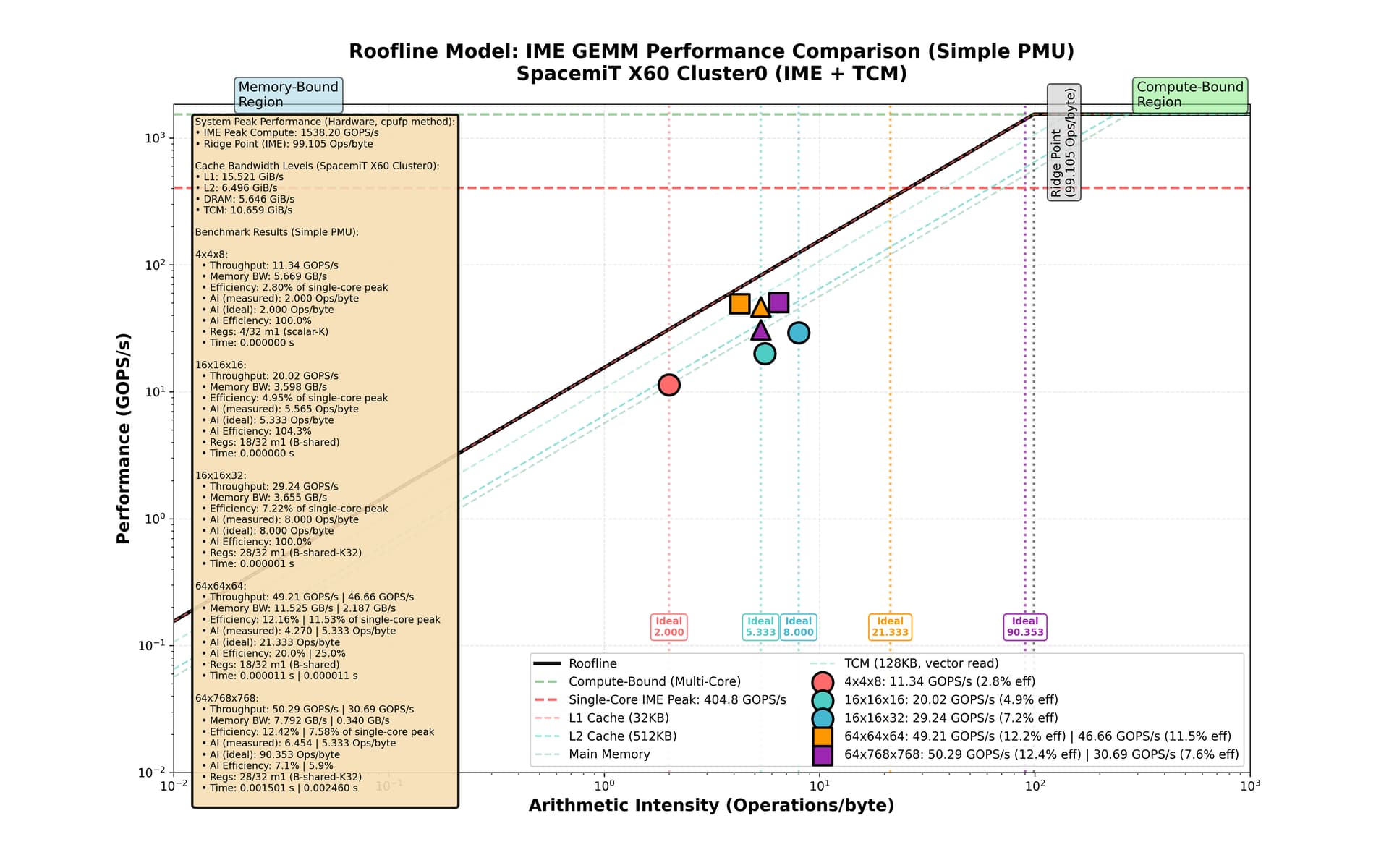
最近优化内核的成果。
貌似已经逼近硬件极限了:32个寄存器,用掉了28个。16x16x16和16x16x32基础微内核的性能略低于DRAM带宽设定的极限,但是基于它俩的更实用的内核已经享受到了缓存的红利,超越了DRAM带宽限定,接近了L1 cache的带宽限定。
最高能够达到的峰值算力使用率接近1/8。
1 个赞